En la actualidad existe una rápida acumulación de publicaciones científicas relacionadas con biomedicina y ciencias de la salud publicadas no solo en inglés, sino en otros idiomas como el español. La relevancia de poder acceder y buscar publicaciones médicas escritas en diversos idiomas se hizo patente durante la pandemia de COVID-19, en la que la necesidad de tener acceso a fuentes de información científica a escala global es crítica.
La biblioteca virtual en salud (BVS), junto con bases de datos bibliográficas como IBECS, LILACS y SciELO ofrecen acceso a literatura que sirven como fuentes de información clave a investigadores y profesionales de la salud para recuperar artículos de importancia para la medicina basada en evidencias, la elaboración de guías clínicas, así como revisiones sistemáticas y elaboración de estudios científicos con el fin último de mejorar la salud de los pacientes.
Realizar búsquedas eficientes en estas fuentes de información requieren a menudo de consultas complejas que dependen de la asignación previa de términos por expertos a estos artículos que describen su contenido. Este proceso, conocido como indexación semántica con vocabularios o términos controlados como MeSH o DeCS en la actualidad es una tarea manual por lo que resulta cada vez más difícil asignar estos términos a un número creciente de publicaciones.
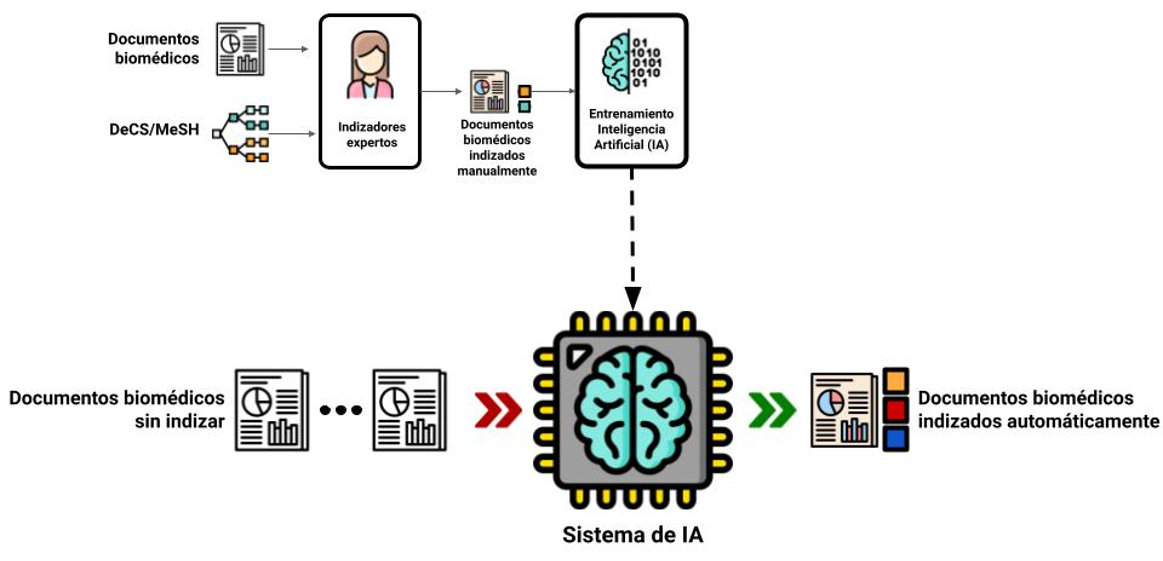 La unidad de Text Mining del Barcelona Supercomputing Center, en el marco del Plan de Impulso de tecnologías del lenguaje (Plan TL) colabora con la Biblioteca Nacional de Ciencias de la Salud (BNCS-ISCIII) y BIREME/OPS/OMS para fomentar el desarrollo de sistemas de indexación semántica basada en los últimos avances de inteligencia artificial y procesamiento del lenguaje natural a través de una competencia internacional llamada MESINESP2 (BioASQ-CLEF2021).
La unidad de Text Mining del Barcelona Supercomputing Center, en el marco del Plan de Impulso de tecnologías del lenguaje (Plan TL) colabora con la Biblioteca Nacional de Ciencias de la Salud (BNCS-ISCIII) y BIREME/OPS/OMS para fomentar el desarrollo de sistemas de indexación semántica basada en los últimos avances de inteligencia artificial y procesamiento del lenguaje natural a través de una competencia internacional llamada MESINESP2 (BioASQ-CLEF2021).
Los participantes de MESINESP2 catalizarán la búsqueda de información biomédica a través de sistemas de indexación semántica basados en rigor científico y en las tecnologías más avanzadas de inteligencia artificial aplicadas a textos en español.
Los sistemas participantes acelerarán estas búsquedas, capaces de recuperar los textos más relevantes sobre literatura médica, así como patentes y ensayos clínicos. Los resultados de MESINESP2 también generarán sistemas de indexación semántica que serán potencialmente útiles para procesar otro tipo de contenido tales como historia clínica electrónica o guías de práctica clínica en escenarios futuros.